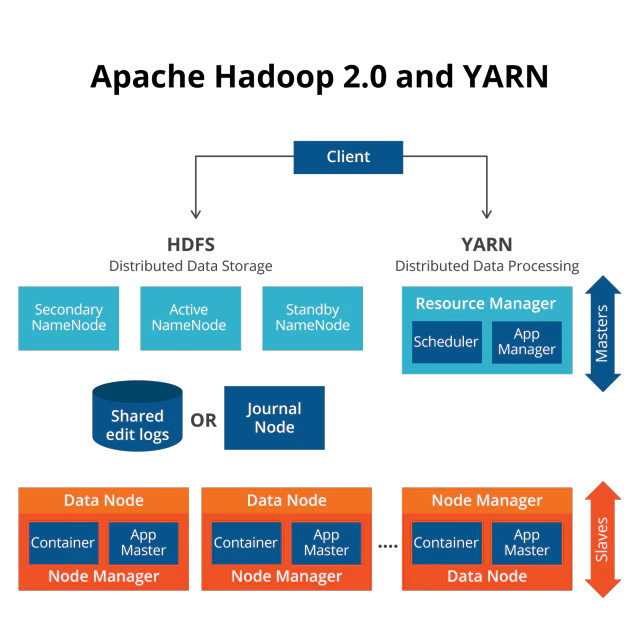
Introduction#
This experiment implements a Fully Distributed Mode cluster deployment of Hadoop HA, HBase HA, and YARN HA using virtual machines.
The list of devices fully suitable for this experiment:
- 2 computers with Oracle VM VirtualBox installed and a virtual machine with Ubuntu Server Linux installed on 1 of them.
- 1 Raspberry Pi 3 Model B.
- 1 router.
- 3 network cables to connect each of the 3 devices to the router.
The equipments you choose do not need to be identical, you can refer to this article according to your own environment, for example:
- If the performance of 1 computer is sufficient for enough VMs to work properly (each of the 2 computers here runs 3 VMs each), 2 and more are not required.
- The introduction of a Raspberry Pi into the cluster is non-essential.
- VirtualBox is not the only optional virtual machine software.
- A wireless router can also be used to build an network environment without network cables.
- ……
How to determine the devices you really need:
- Take an inventory of the number of devices on hand, estimate their performance (to determine how many VMs they can make work).
- Design the cluster rationally to determine ZooKeeper, Hadoop, HBase and YARN deployed on which one of the “machines” (bare or virtual).
- Confirm the number of virtual machines required and assign virtual machines to the host according to the performance of each device.
💡 It is important to note that for more than 1 device, all devices need to be deployed in the same LAN.
The following is a diagram of the services deployed on each machine in this distributed clustering system.
graph TD
subgraph fa:fa-desktop PC_1
H1[fa:fa-server H1
NameNode
zkfc]
H2[fa:fa-server H2
DataNode
HMaster
ResourceManager]
H6[fa:fa-server H6
DataNode
HRegionServer
QuorumPeerMain]
endgraph TD
subgraph fa:fa-desktop PC_2
H4[fa:fa-server H4
NameNode
zkfc]
H5[fa:fa-server H5
DataNode
HMaster
ResourceManager]
H7[fa:fa-server H7
DataNode
HRegionServer
QuorumPeerMain]
endgraph TD
subgraph fa:fa-desktop Raspberry_Pi
H3[fa:fa-server H3
DataNode
HRegionServer
QuorumPeerMain]
endPreparation#
Install apt-transport-https and ca-certificates to enable https sources.
1
| sudo apt install apt-transport-https ca-certificates
|
Backup sources.list.
1
| sudo mv /etc/apt/sources.list /etc/apt/sources.list.bak
|
Modify sources.list.
1
| sudo nano /etc/apt/sources.list
|
Update the software source.
1
2
| sudo apt update
sudo apt upgrade
|
Install openjdk-8-jdk.
1
| sudo apt install openjdk-8-jdk
|
Download Hadoop binary package, and do the same to HBase and ZooKeeper.
1
| wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
|
Unzip to the current directory, and do the same to HBase and ZooKeeper.
1
| tar xzf hadoop-3.3.1.tar.gz
|
Edit .bashrc.
Add relevant environment variables.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| #Hadoop Related Options
export HADOOP_HOME=/home/hadoop/hadoop-3.3.1
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native -Djava.net.preferIPv4Stack=true"
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
#HBase Related Options
export HBASE_HOME=/home/hadoop/hbase-2.4.6
export PATH=$PATH:$HBASE_HOME/sbin:$HBASE_HOME/bin
#ZooKeeper Related Options
export ZOOKEEPER_HOME=/home/hadoop/apache-zookeeper-3.7.0-bin
export PATH=$PATH:$ZOOKEEPER_HOME/bin
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export PATH=$PATH:$JAVA_HOME/bin
|
💡 hadoop in the example is the username, please change it as appropriate, same below.
Make changes to .bashrc take effect.
Modify the sshd_config settings.
1
| sudo nano /etc/ssh/sshd_config
|
1
2
3
4
5
| Port 22
ListenAddress 0.0.0.0
PermitRootLogin yes
PasswordAuthentication yes
X11Forwarding no
|
Restart the ssh service to take effect.
1
| sudo service ssh restart
|
Clone the virtual machine#
Name the previously configured virtual machine H1, clone H2 to H7 (select Full Clone in VirtualBox and select Reinitialize the MAC address of all network cards), and modify the corresponding /etc/hostname and /etc/hosts.
Configure the virtual machine to get a static IP.
1
| sudo nano /etc/netplan/00-installer-config.yaml
|
1
2
3
4
5
6
7
8
9
10
11
| network:
renderer: networkd
ethernets:
enp0s3:
dhcp4: false
addresses: [192.168.0.201/24]
gateway4: 192.168.0.1
nameservers:
addresses: [8.8.8.8]
optional: true
version: 2
|
💡 enp0s3 is the physical network card name, please modify it according to the actual situation, which can be obtained through ip addr; gateway4 refers to the default gateway, which should be consistent with the default gateway setting of the host.
In this cluster, a total of 7 virtual machines from H1 to H7 are configured with static IPs 192.168.0.201 to 192.168.0.207, so the above changes need to be made 7 times.
Apply the changes to take effect.
Check if it is in effect.
The result seems good.
1
2
3
4
5
6
7
8
9
10
11
12
| 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: **enp0s3**: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 08:00:27:9a:bf:e9 brd ff:ff:ff:ff:ff:ff
inet **192.168.0.201**/24 brd 192.168.0.255 scope global enp0s3
valid_lft forever preferred_lft forever
inet6 fe80::a00:27ff:fe9a:bfe9/64 scope link
valid_lft forever preferred_lft forever
|
Modify /etc/hostname.
1
| sudo nano /etc/hostname
|
The content is as follows, which is an example of H1.
Modify /etc/hosts.
The following is an example of H1, commenting out the line that corresponds to the original host name, the place that needs to be changed for different virtual machines is localhost.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| 127.0.0.1 localhost
**## 127.0.1.1 h1**
192.168.0.201 h1
192.168.0.202 h2
192.168.0.203 h3
192.168.0.204 h4
192.168.0.205 h5
192.168.0.206 h6
192.168.0.207 h7
## The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
|
Generate the ssh key.
1
| ssh-keygen -t rsa -P ""
|
Copy the public key to ~/.ssh/authorized_keys.
1
| cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
|
All virtual machines in the cluster copy ssh keys to each other’s virtual machines.
1
2
3
4
5
6
7
| ssh-copy-id hadoop@h1 \
&& ssh-copy-id hadoop@h2 \
&& ssh-copy-id hadoop@h3 \
&& ssh-copy-id hadoop@h4 \
&& ssh-copy-id hadoop@h5 \
&& ssh-copy-id hadoop@h6 \
&& ssh-copy-id hadoop@h7
|
Below is a partial output for copying H1 key.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| hadoop@h1:~$ ssh-copy-id hadoop@h1 && ssh-copy-id hadoop@h2 &&ssh-copy-id hadoop@h3 && ssh-copy-id hadoop@h4 && ssh-copy-id hadoop@h5 && ssh-copy-id hadoop@h6 && ssh-copy-id hadoop@h7
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/hadoop/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: WARNING: All keys were skipped because they already exist on the remote system.
(if you think this is a mistake, you may want to use -f option)
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/hadoop/.ssh/id_rsa.pub"
The authenticity of host 'h2 (192.168.0.202)' can't be established.
ECDSA key fingerprint is SHA256:C6ydAa+dfI5lcMJkMUucz60WE7p3eFLIs7fWZrTYfDE.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
hadoop@h2's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'hadoop@h2'"
and check to make sure that only the key(s) you wanted were added.
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/hadoop/.ssh/id_rsa.pub"
The authenticity of host 'h3 (192.168.0.203)' can't be established.
ECDSA key fingerprint is SHA256:OVEZc5ls6hhBFNgqmZxT/EjubDKr8oyoqwE4Wtvsk+k.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
hadoop@h3's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'hadoop@h3'"
and check to make sure that only the key(s) you wanted were added.
|
Build a ZooKeeper cluster#
Switch to H3.
Copy the ZooKeeper template configuration file and modify the configuration.
1
| cp $ZOOKEEPER_HOME/conf/zoo_sample.cfg $ZOOKEEPER_HOME/conf/zoo.cfg && nano $ZOOKEEPER_HOME/conf/zoo.cfg
|
1
2
3
4
5
| dataDir=/home/hadoop/tmp/zookeeper
server.3=h3:2888:3888
server.6=h6:2888:3888
server.7=h7:2888:3888
|
💡 The cluster information format is server.<id>=<hostname>:2888:3888.
where id is a unique number for each machine and hostname is the corresponding hostname for each machine. For :2888:3888, the former indicates the port on which Follower communicates with the Leader, i.e. the port on which the server communicates internally (default 2888); the latter is the election port (default is 3888).
Create a new dataDir for ZooKeeper on each machine, create a new myid in the directory and fill in the ids, the following is an example of the operation on H3, H6 and H7 respectively.
1
| mkdir -p /home/hadoop/tmp/zookeeper && echo 3 > /home/hadoop/tmp/zookeeper/myid
|
1
| mkdir -p /home/hadoop/tmp/zookeeper && echo 6 > /home/hadoop/tmp/zookeeper/myid
|
1
| mkdir -p /home/hadoop/tmp/zookeeper && echo 7 > /home/hadoop/tmp/zookeeper/myid
|
Copy the ZooKeeper from H3, which you just configured, to H6 and H7.
1
| scp -r $ZOOKEEPER_HOME/conf/* h6:$ZOOKEEPER_HOME/conf && scp -r $ZOOKEEPER_HOME/conf/* h7:$ZOOKEEPER_HOME/conf
|
Start the ZooKeeper service on the 3 machines, i.e., in H3, H6, and H7 and execute the following command.
Check the cluster running status on 3 machines, because the cluster must start at least more than half of the nodes to work properly, so the above command should be executed on 3 machines before you can see the status feedback that the cluster started properly.
The output message means start successfully.
1
2
3
4
5
| hadoop@h3:~$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apache-zookeeper-3.7.0-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
|
1
2
3
4
5
| hadoop@h6:~$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apache-zookeeper-3.7.0-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
|
1
2
3
4
5
| hadoop@h7:~$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apache-zookeeper-3.7.0-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
|
💡 You can see that H6 is currently elected as the Leader.
Get the relevant services that are currently running by executing jps.
1
2
3
| hadoop@h3:~$ jps
2499 Jps
2378 QuorumPeerMain
|
1
2
3
| hadoop@h6:~$ jps
3364 Jps
3279 QuorumPeerMain
|
1
2
3
| hadoop@h7:~$ jps
3511 QuorumPeerMain
3599 Jps
|
Stop the ZooKeeper service on 3 machines, i.e., execute the following command on H3, H6, and H7.
Build a Hadoop cluster#
Switch to H1.
Modify hadoop-env.sh
1
| nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
|
set JAVA_HOME.
1
| export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
|
💡 If there are ARM architecture devices such as Raspberry Pi in the cluster, you should install the corresponding version of JDK and modify the corresponding version of JAVA_HOME, for example.
1
| export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-arm64
|
Modify hdfs-site.xml.
1
| nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
| <configuration>
<!-- Specify the number of replications to be generated -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- Turn off permission restrictions to facilitate development debugging -->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<!-- Name of NameService, consistent with core-site.xml -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- Specify 2 NameNodes -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1 RPC address -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>h1:9000</value>
</property>
<!-- nn1 HTTP address -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>h1:50070</value>
</property>
<!-- nn2 RPC address -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>h4:9000</value>
</property>
<!-- nn2 HTTP address -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>h4:50070</value>
</property>
<!-- JournalNode depends on ZooKeeper and is deployed on the ZooKeeper machine -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://h3:8485;h6:8485;h7:8485/ns1</value>
</property>
<!-- Specify where the JournalNode stores edits data on local disk -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/tmp/journaldata</value>
</property>
<!-- Enable automatic failover for NameNode -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- Configurate failover proxy provider -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- Configurate fencing methods -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- To use the sshfence isolation mechanism, you need to be ssh login free -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- Configure the sshfence isolation mechanism timeout in ms -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<!-- The directory where the FsImage image is saved -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/namenode</value>
</property>
<!-- The directory where the HDFS file system data files are stored -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/datanode</value>
</property>
<property>
<name>heartbeat.recheck.interval</name>
<value>2000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>1</value>
</property>
</configuration>
|
💡 Split-Brain: 2 namenodes are serving at the same time, there are 2 isolation methods available for this.
- sshfence: remote login to kill the namenode in question (if the port number of the remote ssh login is not 22, you need to configure
sshfence(username:port number) at dfs.ha.fencing.methods. - shell: the subsequent solution for unresponsive remote login timeout, you can fill in the custom script in parentheses, such as
shell(/bin/true), then return true to switch directly.
Modify core-site.xml.
1
| nano $HADOOP_HOME/etc/hadoop/core-site.xml
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| <configuration>
<!-- Specify the NameService for HDFS as ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1/</value>
</property>
<!-- Specify the Hadoop tmp directory -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp/hadoop</value>
</property>
<!-- Specify the ZooKeeper addresses -->
<property>
<name>ha.zookeeper.quorum</name>
<value>h3:2181,h6:2181,h7:2181</value>
</property>
<!-- Number of client connection retries -->
<property>
<name>ipc.client.connect.max.retries</name>
<value>100</value>
</property>
<!-- The time interval between 2 connection re-establishments in ms -->
<property>
<name>ipc.client.connect.retry.interval</name>
<value>5000</value>
</property>
</configuration>
|
Modify mapred-site.xml.
1
| nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| <configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop-3.3.1</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop-3.3.1</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop-3.3.1</value>
</property>
</configuration>
|
Modify yarn-site.xml.
1
| nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
| <configuration>
<!-- Enable ResourceManager High Availability -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- Specify ResourceManager cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- Specify the name of the ResourceManager under the group -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- Configure RM1 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>h2</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>h2:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>h2:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>h2:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>h2:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>h2:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm1</name>
<value>h2:23142</value>
</property>
<!-- Configure RM2 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>h5</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>h5:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>h5:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>h5:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>h5:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>h5:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm2</name>
<value>h5:23142</value>
</property>
<!-- Specify the ZooKeeper cluster address -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>h3:2181,h6:2181,h7:2181</value>
</property>
<!-- The reducer fetches data as mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
|
Configure workers.
1
| nano $HADOOP_HOME/etc/hadoop/workers
|
Create the directory needed in the configuration file above.
1
| mkdir -p /home/hadoop/tmp/journaldata /home/hadoop/tmp/hadoop
|
Copy the Hadoop from H1, which you just configured, to the other 6 machines.
1
2
3
4
5
6
| scp -r $HADOOP_HOME/etc/hadoop/* h2:$HADOOP_HOME/etc/hadoop \
&& scp -r $HADOOP_HOME/etc/hadoop/* h3:$HADOOP_HOME/etc/hadoop \
&& scp -r $HADOOP_HOME/etc/hadoop/* h4:$HADOOP_HOME/etc/hadoop \
&& scp -r $HADOOP_HOME/etc/hadoop/* h5:$HADOOP_HOME/etc/hadoop \
&& scp -r $HADOOP_HOME/etc/hadoop/* h6:$HADOOP_HOME/etc/hadoop \
&& scp -r $HADOOP_HOME/etc/hadoop/* h7:$HADOOP_HOME/etc/hadoop
|
Switch to H4 to create a new directory for NameNode to save the FsImage image.
1
| mkdir -p /home/hadoop/data/namenode
|
Start HDFS HA#
Start the ZooKeeper service for H3, H6, and H7, i.e., execute the following commands in H3, H6, and H7.
Check the status of clusters on H3, H6, and H7.
The output message is good.
1
2
3
4
5
| hadoop@h3:~$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apache-zookeeper-3.7.0-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
|
1
2
3
4
5
| hadoop@h6:~$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apache-zookeeper-3.7.0-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
|
1
2
3
4
5
| hadoop@h7:~$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apache-zookeeper-3.7.0-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
|
💡 You can see that H6 is still elected as the Leader.
Start the JournalNode service of H2, H3, H5, H6, and H7, i.e., execute the following command in H2, H3, H5, H6, and H7.
1
| hdfs --daemon start journalnode
|
💡 You need to start the JournalNode manually when the Hadoop cluster starts for the first time, the above steps are not required later.
Get the relevant services that are currently running by executing jps.
1
2
3
| hadoop@h2:~$ jps
4631 Jps
4588 JournalNode
|
1
2
3
4
| hadoop@h3:~$ jps
2864 JournalNode
2729 QuorumPeerMain
2938 Jps
|
1
2
3
| hadoop@h5:~$ jps
4371 Jps
4325 JournalNode
|
1
2
3
4
| hadoop@h6:~$ jps
3474 QuorumPeerMain
3594 JournalNode
3644 Jps
|
1
2
3
4
| hadoop@h7:~$ jps
3890 Jps
3848 JournalNode
3736 QuorumPeerMain
|
Switch to H1 to format HDFS.
Copy the FSImage from the H1 NameNode to the H4 NameNode, making sure they are identical.
1
| scp -r /home/hadoop/data/namenode/* h4:/home/hadoop/data/namenode
|
Format ZKFC.
Start HDFS.
Get the relevant services that are currently running by executing jps.
1
2
3
4
| hadoop@h1:~$ jps
22368 Jps
21960 NameNode
22317 DFSZKFailoverController
|
A review of the report shows that the status of the 5 DataNodes is alive.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
| Configured Capacity: 101142011904 (94.20 GB)
Present Capacity: 59280982016 (55.21 GB)
DFS Remaining: 59280859136 (55.21 GB)
DFS Used: 122880 (120 KB)
DFS Used%: 0.00%
Replicated Blocks:
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
Erasure Coded Block Groups:
Low redundancy block groups: 0
Block groups with corrupt internal blocks: 0
Missing block groups: 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
-------------------------------------------------
Live datanodes (5):
Name: 192.168.0.202:9866 (h2)
Hostname: ip6-localhost
Decommission Status : Normal
Configured Capacity: 9971224576 (9.29 GB)
DFS Used: 24576 (24 KB)
Non DFS Used: 7673147392 (7.15 GB)
DFS Remaining: 1771356160 (1.65 GB)
DFS Used%: 0.00%
DFS Remaining%: 17.76%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 0
Last contact: Mon Oct 25 02:17:04 UTC 2021
Last Block Report: Mon Oct 25 02:15:29 UTC 2021
Num of Blocks: 0
Name: 192.168.0.203:9866 (h3)
Hostname: ip6-localhost
Decommission Status : Normal
Configured Capacity: 61257113600 (57.05 GB)
DFS Used: 24576 (24 KB)
Non DFS Used: 6547861504 (6.10 GB)
DFS Remaining: 52175802368 (48.59 GB)
DFS Used%: 0.00%
DFS Remaining%: 85.18%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 0
Last contact: Mon Oct 25 02:17:06 UTC 2021
Last Block Report: Mon Oct 25 02:15:54 UTC 2021
Num of Blocks: 0
Name: 192.168.0.205:9866 (h5)
Hostname: ip6-localhost
Decommission Status : Normal
Configured Capacity: 9971224576 (9.29 GB)
DFS Used: 24576 (24 KB)
Non DFS Used: 7665070080 (7.14 GB)
DFS Remaining: 1779433472 (1.66 GB)
DFS Used%: 0.00%
DFS Remaining%: 17.85%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 0
Last contact: Mon Oct 25 02:17:06 UTC 2021
Last Block Report: Mon Oct 25 02:15:33 UTC 2021
Num of Blocks: 0
Name: 192.168.0.206:9866 (h6)
Hostname: ip6-localhost
Decommission Status : Normal
Configured Capacity: 9971224576 (9.29 GB)
DFS Used: 24576 (24 KB)
Non DFS Used: 7667515392 (7.14 GB)
DFS Remaining: 1776988160 (1.65 GB)
DFS Used%: 0.00%
DFS Remaining%: 17.82%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 0
Last contact: Mon Oct 25 02:17:05 UTC 2021
Last Block Report: Mon Oct 25 02:15:38 UTC 2021
Num of Blocks: 0
Name: 192.168.0.207:9866 (h7)
Hostname: ip6-localhost
Decommission Status : Normal
Configured Capacity: 9971224576 (9.29 GB)
DFS Used: 24576 (24 KB)
Non DFS Used: 7667224576 (7.14 GB)
DFS Remaining: 1777278976 (1.66 GB)
DFS Used%: 0.00%
DFS Remaining%: 17.82%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 0
Last contact: Mon Oct 25 02:17:07 UTC 2021
Last Block Report: Mon Oct 25 02:15:31 UTC 2021
Num of Blocks: 0
|
Test HDFS HA#
Visit http://192.168.0.201:50070/ You can see ‘h1:9000’ (active)
Stop the NameNode at H1.
1
| hdfs --daemon stop namenode
|
At this point visit http://192.168.0.204:50070/ to see ‘h4:9000’ (active).
Enable NameNode again in H1.
1
| hdfs --daemon start namenode
|
At this point visit http://192.168.0.204:50070/ to see ‘h1:9000’ (standby).
Start YARN#
Start the YARN service of H2 and H5, i.e., execute the following command in H2.
Get the relevant services that are currently running by executing jps.
1
2
3
4
5
6
| hadoop@h2:~$ jps
5203 JournalNode
6691 NodeManager
6534 ResourceManager
6838 Jps
5692 DataNode
|
1
2
3
4
5
6
| hadoop@h5:~$ jps
6099 Jps
5395 DataNode
4921 JournalNode
5659 ResourceManager
5789 NodeManager
|
Test YARN HA#
Visit http://192.168.0.202:8188/ to see ResourceManager HA state: active.
Stop ResourceManager in H2.
1
| yarn --daemon stop resourcemanager
|
At this point visit http://192.168.0.205:8188/ and you can see ResourceManager HA state: active.
The NameNode is enabled again in H2.
1
| yarn --daemon start resourcemanager
|
At this point visit http://192.168.0.202:8188/ and you can see ResourceManager HA state: standby.
Test MapReduce#
Switch to H2.
1
| hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi 1 1
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
| hadoop@h2:~$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi 1 1
Number of Maps = 1
Samples per Map = 1
Wrote input for Map #0
Starting Job
2021-10-25 07:08:04,762 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
2021-10-25 07:08:04,977 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/hadoop/.staging/job_1635145651320_0001
2021-10-25 07:08:05,934 INFO input.FileInputFormat: Total input files to process : 1
2021-10-25 07:08:06,626 INFO mapreduce.JobSubmitter: number of splits:1
2021-10-25 07:08:06,973 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1635145651320_0001
2021-10-25 07:08:06,975 INFO mapreduce.JobSubmitter: Executing with tokens: []
2021-10-25 07:08:07,341 INFO conf.Configuration: resource-types.xml not found
2021-10-25 07:08:07,342 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2021-10-25 07:08:07,991 INFO impl.YarnClientImpl: Submitted application application_1635145651320_0001
2021-10-25 07:08:08,048 INFO mapreduce.Job: The url to track the job: http://h5:8188/proxy/application_1635145651320_0001/
2021-10-25 07:08:08,051 INFO mapreduce.Job: Running job: job_1635145651320_0001
2021-10-25 07:08:25,438 INFO mapreduce.Job: Job job_1635145651320_0001 running in uber mode : false
2021-10-25 07:08:25,439 INFO mapreduce.Job: map 0% reduce 0%
2021-10-25 07:08:34,585 INFO mapreduce.Job: map 100% reduce 0%
2021-10-25 07:08:50,737 INFO mapreduce.Job: map 100% reduce 100%
2021-10-25 07:08:52,774 INFO mapreduce.Job: Job job_1635145651320_0001 completed successfully
2021-10-25 07:08:52,993 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=28
FILE: Number of bytes written=555793
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=255
HDFS: Number of bytes written=215
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=5590
Total time spent by all reduces in occupied slots (ms)=14233
Total time spent by all map tasks (ms)=5590
Total time spent by all reduce tasks (ms)=14233
Total vcore-milliseconds taken by all map tasks=5590
Total vcore-milliseconds taken by all reduce tasks=14233
Total megabyte-milliseconds taken by all map tasks=5724160
Total megabyte-milliseconds taken by all reduce tasks=14574592
Map-Reduce Framework
Map input records=1
Map output records=2
Map output bytes=18
Map output materialized bytes=28
Input split bytes=137
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=28
Reduce input records=2
Reduce output records=0
Spilled Records=4
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=220
CPU time spent (ms)=1050
Physical memory (bytes) snapshot=302690304
Virtual memory (bytes) snapshot=4986265600
Total committed heap usage (bytes)=138096640
Peak Map Physical memory (bytes)=202854400
Peak Map Virtual memory (bytes)=2490499072
Peak Reduce Physical memory (bytes)=99835904
Peak Reduce Virtual memory (bytes)=2495766528
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=118
File Output Format Counters
Bytes Written=97
Job Finished in 48.784 seconds
Estimated value of Pi is 4.00000000000000000000
|
Build an HBase HA cluster#
Switch to H2.
Modify hbase-env.sh.
1
| nano $HBASE_HOME/conf/hbase-env.sh
|
Set JAVA_HOME。
1
| export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
|
💡 Similarly, if there are ARM architecture devices such as Raspberry Pi in the cluster, you should install the corresponding version of JDK and modify the corresponding version of JAVA_HOME, such as
1
| export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-arm64
|
Does not use the HBase provided ZooKeeper.
1
| export HBASE_MANAGES_ZK=false
|
Modify hbase-site.xml。
1
| nano $HBASE_HOME/conf/hbase-site.xml
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| <configuration>
<!-- Specify the path to where HBase is stored on HDFS -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://ns1/hbase</value>
</property>
<!-- Specifying if HBase is distributed -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- Specify the ZooKeeper addresses -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>h3:2181,h6:2181,h7:2181</value>
</property>
<!-- Specify the maximum time difference between HMaster and HRegionServer -->
<property>
<name>hbase.master.maxclockskew</name>
<value>180000</value>
</property>
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value>
</property>
</configuration>
|
Modify regionservers。
1
| nano $HBASE_HOME/conf/regionservers
|
Copy core-site.xml and hdfs-site.xml from H1 to H2.
1
2
| scp -r $HADOOP_HOME/etc/hadoop/core-site.xml h2:$HBASE_HOME/conf \
&& scp -r $HADOOP_HOME/etc/hadoop/hdfs-site.xml h2:$HBASE_HOME/conf
|
Replicate the HBase in H2 that you just configured to the other 4 machines.
1
2
3
4
| scp -r $HBASE_HOME/conf/* h3:$HBASE_HOME/conf \
&& scp -r $HBASE_HOME/conf/* h5:$HBASE_HOME/conf \
&& scp -r $HBASE_HOME/conf/* h6:$HBASE_HOME/conf \
&& scp -r $HBASE_HOME/conf/* h7:$HBASE_HOME/conf
|
Start HBase HA#
Switch to H1.
Start HDFS.
Get the relevant services that are currently running by executing jps.
1
2
3
4
| hadoop@h1:~$ jps
3783 NameNode
4169 Jps
4138 DFSZKFailoverController
|
Switch to H2.
Start HMaster.
Switch to H5.
Start HMaster.
1
| hbase-daemon.sh start master
|
Get the relevant services that are currently running by executing jps.
1
2
3
4
5
| hadoop@h2:~$ jps
1052 JournalNode
7901 DataNode
8125 HMaster
8847 Jps
|
1
2
3
4
5
6
| hadoop@h3:~$ jps
6368 Jps
6210 HRegionServer
2660 QuorumPeerMain
5717 DataNode
5846 JournalNode
|
1
2
3
4
5
| hadoop@h5:~$ jps
6336 Jps
1058 JournalNode
6117 HMaster
5980 DataNode
|
1
2
3
4
5
6
| hadoop@h6:~$ jps
4722 Jps
4408 JournalNode
4248 DataNode
4570 HRegionServer
1039 QuorumPeerMain
|
1
2
3
4
5
6
| hadoop@h7:~$ jps
4402 DataNode
4563 JournalNode
4726 HRegionServer
1031 QuorumPeerMain
5000 Jps
|
Test HBase HA#
Visit http://192.168.0.202:16010/ to see Current Active Master: h2.
Stop HMaster at H2.
1
| hbase-daemon.sh stop master
|
At this point visit http://192.168.0.205:16010/ to see Current Active Master: h5.
Start HMaster again in H2.
1
| hbase-daemon.sh start master
|
At this point visit http://192.168.0.202:16010/ and you will see Current Active Master: h5 and Backup Master is h2.
Great work#
The end of the process is the beginning of the learning curve. Keep smiling and keep progressing 😊